Rubrik recently presented at Tech Field Day 12 and one of the sessions focused on our distributed filesystem called Atlas. As one of the SE’s at Rubrik I’m in the field every day (proudly) representing my company but also competing with other, more traditional backup and recovery vendors. What is apparent more and more is that these traditional vendors are also going down the appliance route to sell their solution into the market, and as such I sometimes get the pushback from potential customers saying they can also get an appliance based offer from their current supplier, or not really immediately grasping why this model can be beneficial to them. A couple of things I wanted to clarify first, when I say “also down the appliance route” I need make clear that this is purely a way to offer the solution to market for us, there is nothing special about the appliance as such, all of the intelligence in Rubrik’s case lies in the software, we even started to offer a software only version in the form of a virtual appliance for ROBO use cases recently.
Secondly, some traditional vendors can indeed deliver their solution in an appliance based model, be it their own branded one, or pre-packaged via a partnership with a traditional hardware vendor. I’m not saying there is something inherently bad about this, simplifying the acquisition of a backup solution via an appliance based model is great, but there the comparison stops, it will still be a legacy based architecture with disparate software components, typically these software components, think media server, database server, search server, storage node, etc. need individual love and care, daily babysitting if you will, to keep them going. Lastly from a component point of view our appliance consists of multiple independent (masterless) nodes that are each capable of running all tasks of the data management solution, in other words there is no need to protect, or indeed worry about, individual software and hardware components as everything is running distributed and able to sustain multiple failures while remaining operational.

So the difference lies in the software architecture, not the packaging, as such we need to look beyond the box itself and dive into why starting from a clustered distributed system as a base makes much more sense in todays information era.
The session at TFD12 was presented by Adam Gee and Roland Miller, Adam is the lead of Rubrik’s distributed filesystem called Atlas, it shares some architectural principles with a previous filesystem Adam worked on while he was at Google called Colossus, most items you store while using Google services end up on Colossus, it itself is the successor to the Google File System (GFS) bringing the concept of a masterless cluster to it and making it much more scalable. Not a lot is available on the web in terms of technical details around Colossus, but you can read a high level article on Wired about it here.
Atlas, which sits at the core of the Rubrik architecture, is a distributed filesystem, built from scratch with the Rubrik data management application in mind. It uses all distributed local storage (DAS) resources available on all nodes in the cluster and pools them together into a global namespace. As nodes are added to the cluster the global namespace grows automatically, increasing capacity in the cluster. The local storage resources on each node consist of both SSD and HDD’s, the metadata of Atlas (and the metadata of the data management application) is stored in the metadata store (Callisto) which is also running distributed on all nodes in the SSD layer. The nodes communicate internally using RPC which are presented to Atlas by the cluster management component (Forge) in a topology aware manner thus giving Atlas the capability to provide data locality. This is needed to ensure that data is spread correctly throughout the cluster for redundancy reasons. For example, assuming we are using triple mirror, we need to store data in 3 different nodes in the appliance, let’s now assume the cluster grows beyond 1 appliance, then it would make more sense from a failure domain point of view to move 1 copy of the data from one of the local nodes to the other appliance.
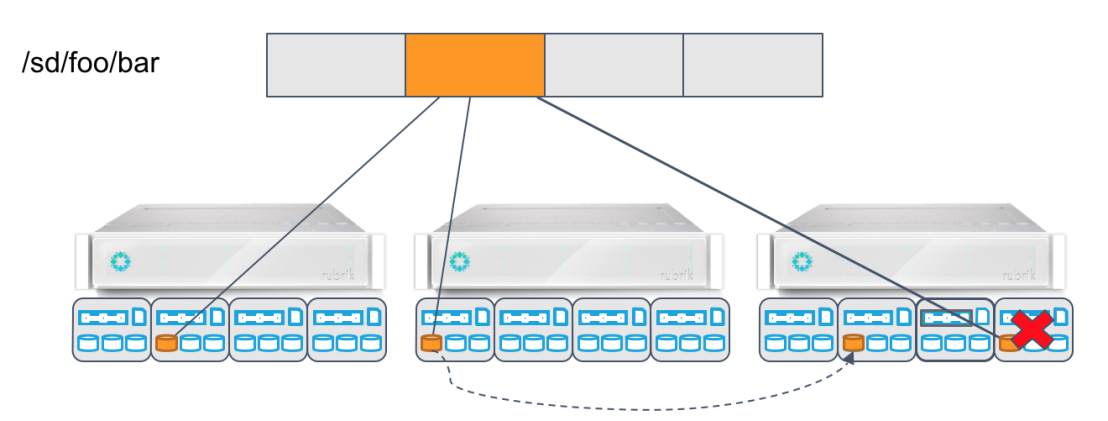
The system is self healing in the way that Forge publishes the disk and node health status and Atlas can react to that, again assuming triple mirror, if a node or entire brik (appliance) fails Atlas will create a new copy of the data on another node to make sure the requested failure tolerance is met. Additionally Atlas also runs a background task to check the CRC of each chunk of data to ensure what you have written to Rubrik is available in time of recovery. See the article How To Kill A Supercomputer: Dirty Power, Cosmic Rays, and Bad Solder on why that could be important.
The Atlas filesystem was designed with the data management application in mind, essentially the application takes backups and places them on Atlas, building snapshots chains (Rubrik performs an initial full backup and incremental forever after that). The benefit is that we can instantly materialize any point in time snapshot without the need to re-hydrate data.
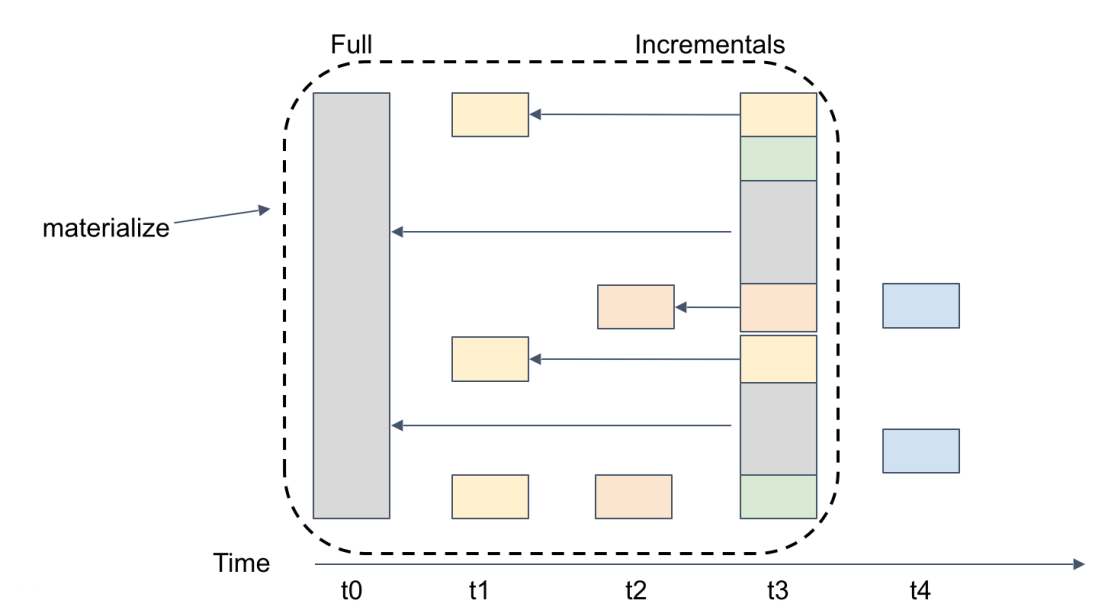
In the example above you have the first full backup at t0, and then 4 incremental backups after that. Let’s assume you want to instantly recover data at point t3, this will simply be a metadata operation, pointers to the last time blocks making up t3 where mutated, there is no data movement involved.
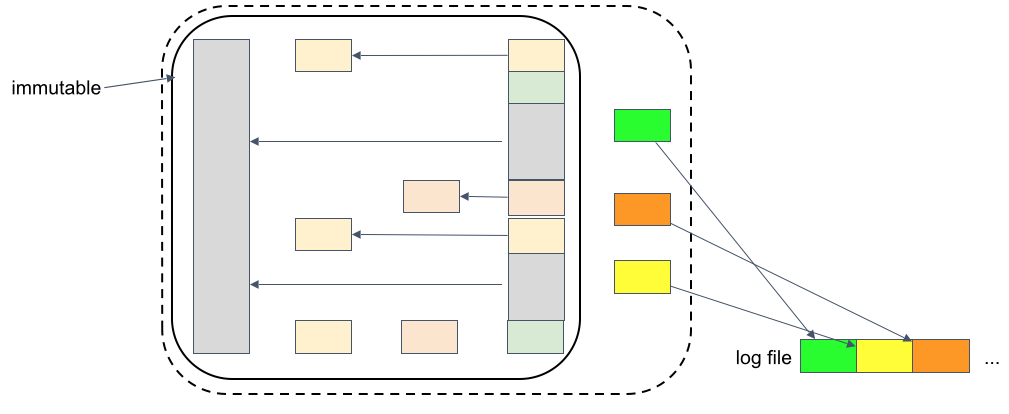
Taking it a step further let’s now assume you want to use t3 as the basis and start writing new data to it from that point on. Any new data that you write to it (redirect-on-write) now goes to a log file, no content from the original snapshot is changed as this needs to be an immutable copy (compliancy). The use case here could be copy data management where you want to present a copy of a dataset to internal dev/test teams.
Atlas also dynamically provides performance for certain operations in the cluster, for example a backup ingest job will get a higher priority than a background maintenance task. Because each node also has a local SSD drive Atlas can use this to place critical files on a higher performance tier and is also capable of tiering all data and placing hot blocks on SSDs. It also understands that each node has 3 HDDs and will these to stripe the data of a file across all 3 on a single node to take advantage of the aggregate disk bandwidth resulting in a performance improvement on large sequential reads and writes, by utilizing read-ahead and write buffering respectively.
For more information on Atlas you can find the blogpost Adam Gee wrote on it here, or watch the TFD12 recording here.