With the announcement of Rubrik CDM version 4, codenamed Alta, we have added tons of new features to the platform, but since most of the release announcements are focussed on providing an overview of all the goodies, I wanted to focus more deeply on one specific topic namely our integration with AWS.
Rubrik has had a long history of successfully working with Amazon Web Services, we’ve had integration with Amazon S3 since our first version. In our initial release you could already use Amazon S3 as an archive location for on-premises backups, meaning take local backups of VMware Virtual Machines and then keep them on the local Rubrik cluster for a certain period of time (short term retention) with the option to put longer term retention data into Amazon S3. The idea was to leverage cloud storage economics and resiliency for backup data and at the same time have an active archive for longer term retention data instead of an offline copy on tape. Additionally the way our metadata system works allows us to only retrieve the specific bits of data you need to restore instead of having to pull down the entire VMDK file and incurring egress costs potentially killing the cloud storage economics benefit.
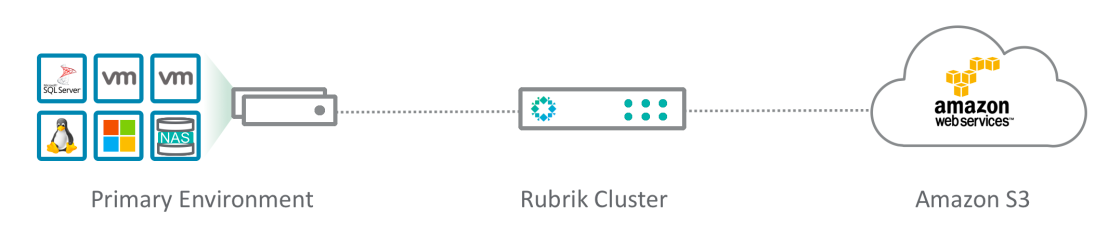
Also note there is no need to put a gateway device between the Rubrik cluster and Amazon S3, instead Rubrik can natively leverage the S3 APIs.
The ability to archive to Amazon S3 is still here in version 4 of course but now all the supported sources besides VMware ESXi, like Microsoft Hyper-V, Nutanix AHV, Physical Windows/Linux, Native SQL, and so on can also leverage this capability.
Then in Rubrik CDM version 3.2 we added the ability to protect native AWS workloads by having a Rubrik cluster run inside AWS using EC2 for compute and EBS for storage.
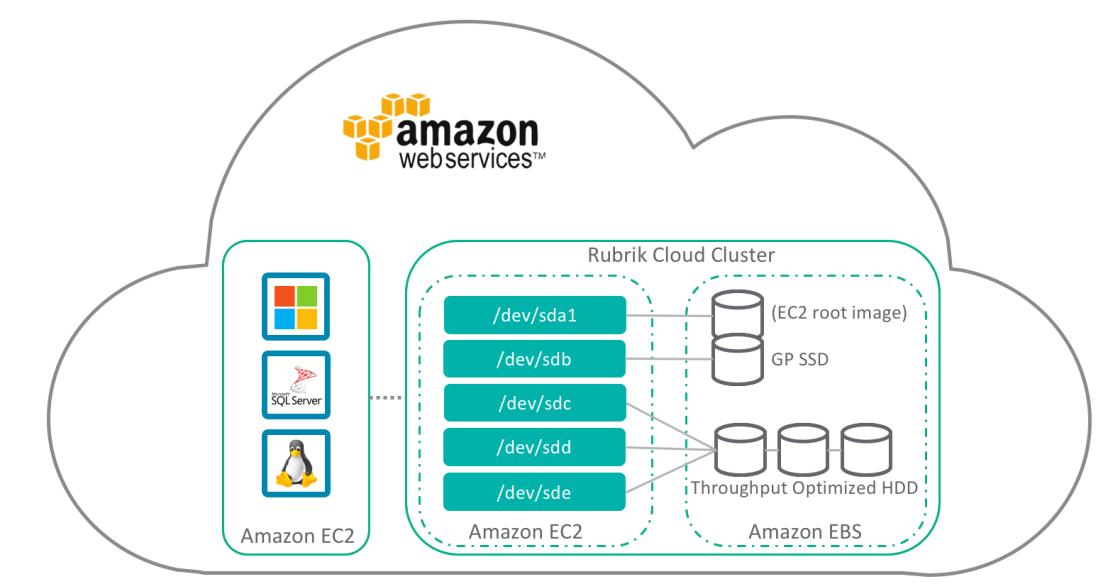
We’ll run a 4 node (protecting your data using Erasure Coding) Rubrik cluster in you preferred AWS location (the Rubrik AMI image is uploaded as a private image). We use the m4.xlarge instance type, using 64GB RAM, 256GB SSD (GP SSD (GP2)) and 24TB Raw Capacity (Throughput Optimised HDD (ST1)), resulting in 15TB usable capacity before deduplication and compression.
Once the Cloud Cluster is running you can protect your native AWS workloads using the connector based approach, i.e. you can protect Windows and Linux filesets, and Native SQL workloads in the Public Cloud.
Additionally since potentially you can now have a Rubrik cluster on-premises and a Rubrik Cloud Cluster you can replicate from your in-house datacenter to your public cloud environment and vice versa. Or replicate from one AWS region to another.

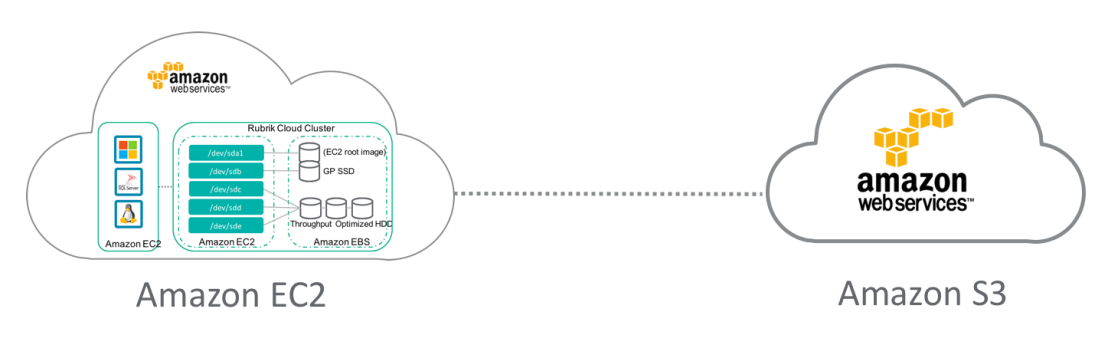
Since the Cloud Cluster has the same capabilities as the on-premises one it can also backup your AWS EC2 workloads and then archive the data to S3, essentially going from EBS storage to S3. (Christopher Nolan really likes this feature).
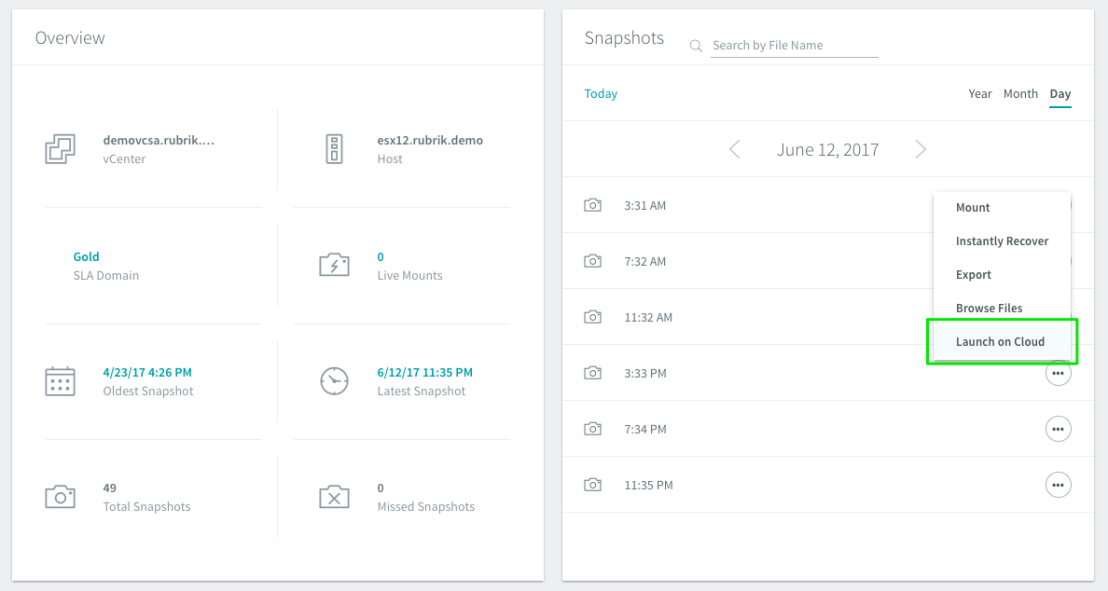
Version 4 of Rubrik CDM extends our AWS capabilities by delivering on-demand app mobility, called CloudOn. The idea is that now you can take an application that is running on-premises and move it on the fly to AWS for DR, or Dev/Test, or analytics scenarios.

The way it will work is that just as since v1 you archive your data to AWS S3, once you decide to instantiate that workload in the public cloud you select “Launch On Cloud” from the Rubrik interface and a temporary Rubrik node (spun up on-demand in AWS in the VPC of your choice) converts those VMs into cloud instances (i.e. going from VMware ESXi to AWS AMI images). Once complete the temporary Rubrik node powers down and is purged.
Rubrik scans the configuration file of a VM to understand its characteristics (compute, memory, storage, etc.) and recommends a compatible cloud instance type so you are not left guessing what resources you need to consume on AWS.
Alternatively we can also auto-convert the latest snapshot going to S3 so you don’t have to wait for the conversion action.
Data has gravity, meaning that once you accumulate more and more data it starts to make more sense to move the application closer to the data since the other way around starts to become less performant, and more and more cost prohibitive in terms of transport costs. So what if your data sits on-premises but your applications are running in the public cloud?
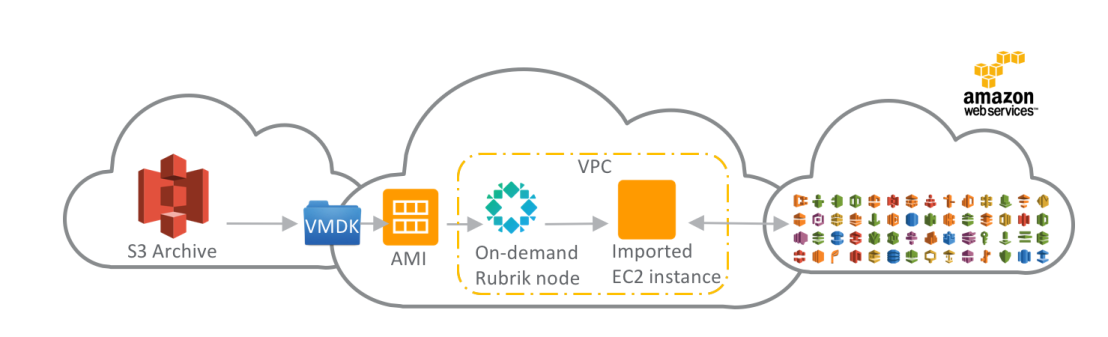
For instance let’s say you want to perform business analytics using Amazon QuickSight but your primary data sources are in your private data center, now you simply archive data to S3 as part of your regular Rubrik SLA (archive data older than x days) and pick the point-in-time dataset you are interested in, use Rubrik to “Launch on Cloud”, and point Amazon QuickSight (or any other AWS service) to your particular data source.
Together these AWS integrations allow you to make use of the public cloud on your terms, in an extremely flexible way.