I’ve written a blog post about Atlas, our distributed filesystem before, where I tried to differentiate between pre-packaged solutions, ultimately using existing legacy architectures with inherited build-in single points of failures, and a truly distributed system where each node in the cluster can perform all of the tasks that are required for successful operation of said cluster.
Atlas is just one piece of the puzzle, we need to further differentiate between using a partially distributed system design, i.e. using a distributed storage layer, in combination with a legacy management architecture, and using a distributed storage layer as part of a modern masterless architecture. In the case of Rubrik, all components operate in a distributed, masterless design. Each 2U appliance contains 4 individual nodes (individual servers), each individual server runs our Cloud Data Management solution as part of the bigger overall cluster. If a node (or an individual component inside a node) fails it has no impact on the overall correct operation of the cluster. The only component that is shared is the redundant power supply.
Can the same be said of running a legacy software stack on top of a distributed storage layer? Are all components running completely distributed? If the management components fail, does a distributed storage layer help you?
Let’s start by looking at a legacy stack example;
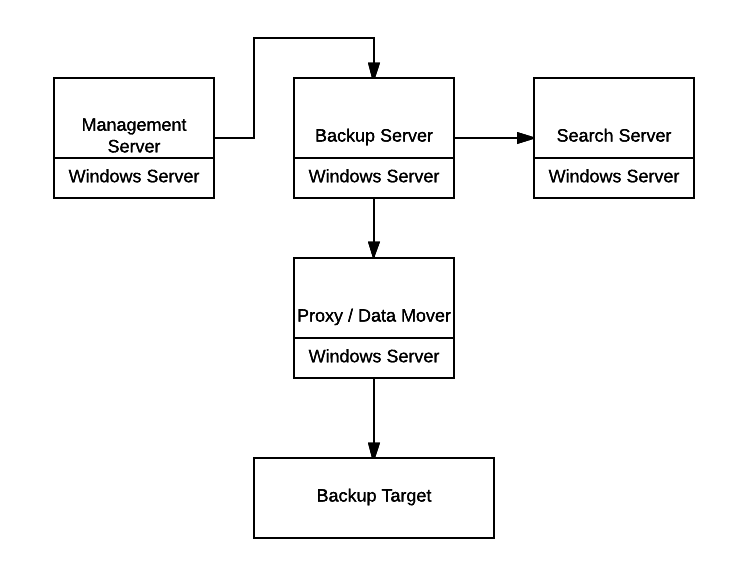
f you think about this from the pov of taking a backup, most of these components have a role to play. If one of the components is not operational no backups are taken, and the RPO keeps increasing until the backup solution is repaired.
Now let’s focus on distributing part of the legacy stack;
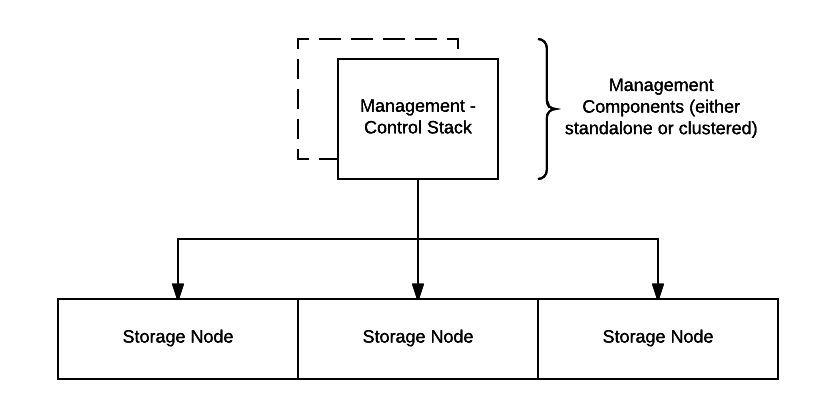
Again thinking about this from the pov of taking a backup, assuming the system/management components are operational you now have a scale-out, redundant storage layer which brings additional flexibility but it does not lessen the burden on the rest of the stack. If something in the system/management layer fails having a redundant storage layer does not save you, you are again increasing your RPO until the infrastructure is restored.
Now contrast this with Rubrik’s masterless approach;
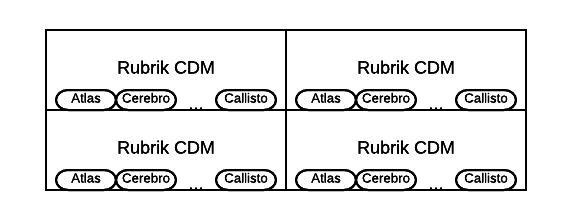
Seeing that all processes (we don’t have the traditional demarcations of media server, search server, proxy/data mover, etc, but we do run processes/applications in a distributed manner in the cluster that provide all the CDM functions) are running on all nodes, we can similarly lose hardware components (because everything fails eventually) but this will not bring down the master server, simply because we don’t have a master server. Let’s say a node is working on ingesting backup data from your primary system and the node fails, the task is not marked as complete in our distributed system so another node in the cluster will pick up the job and make sure the backup is taken.
Rubrik has opted to build a truly scalable, masterless cluster, neatly leapfrogging legacy approaches of the past by taking lessons from massive-scale modern environments found at Google, Facebook and the like. To be fair, when legacy backup system where designed these giants’ shoulders were not available…
The bigger picture
Even though the principles and technology behind Rubrik are fascinating, it is important not to lose sight of the bigger picture. The idea is to deliver a greatly simplified approach to data management, that the architecture is a converged, masterless, scale-out, self-healing system, etc is nice but the real benefit lies in the operational use.
An additional benefit of using this design is that because we have a unified system, we can present this via a unified RESTful API. Integrating/automating the storage target, or integrating with the management components is not separate, simply because the system is one. Now contrast that with running multiple different components, each with their own, or non-existing integration points, the practical experience with be night and day. A better (much better) experience is ultimately what we are after, after all.
And finally, I wanted to point out that the pictures above are sort of looking at a traditional type of on-premises only environment, but what about running in the public cloud, multi-cloud, hybrid environment, branch offices, etc? Again the model we use delivers the flexibility to run anywhere since you don’t have to drag around these legacy interlinked pieces.